From July 2018, the Europe PMC repository will start indexing preprints. Making preprints discoverable through Europe PMC will make the science reported in preprints more widely discoverable and support their inclusion into workflows such as grant reporting, article citing and credit and attribution. This blog post explains why we have done this, and discusses some of the opportunities and challenges that arise from this decision.
![]()
![]()
In the life sciences, peer reviewed journal articles are the global currency by which we share research results, used also, in part, in funding and career decisions. But in the past few years the use of preprints - non-peer reviewed articles, posted to preprint servers - has become increasingly popular. According to Jordan Anaya of PrePubMed, over 2300 new life sciences preprints were published in June 2018 (see Fig.1), in large part driven by the use of bioRxiv.
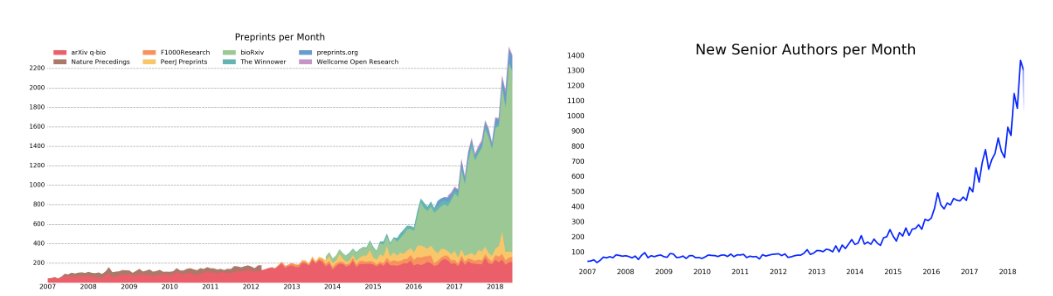
The very widespread use of preprints for biologists has a long way to go - the rate of growth is impressive, but still, as measured against the monthly ingest of peer reviewed papers by PubMed, it represents only 2-3 % of that volume. While the use of preprints has been particularly popular in computational biology and genomics, questions remain for many researchers on the long-term benefits of preprints. In recognition both of the trending popularity and the need to better understand the effect of preprints on the publishing ecosystem, Europe PMC will now be including preprint records.
Europe PMC and preprints
From July 2018, Europe PMC will include abstracts for preprints that have a DOI and can be retrieved via Crossref metadata services. This means that about 37,000 preprints will be immediately discoverable in Europe PMC; a figure which we anticipate will grow by around 2000 preprints every month.
By restricting Crossref searches by DOI prefix, the initial preprint servers to be indexed include: bioRxiv, PeerJ Preprints, ChemRxiv, F1000Res, and the Open Research platforms powered by F1000: Gates Open Res, Wellcome Open Res, HRB Open Res, AAS Open Res, and MNI Open Res. We are using this filtering approach in order to include preprints that have screening protocols in place, and to ensure we do not inadvertently include blog posts or other types of non-peer reviewed content. You can expect to find preprints in Europe PMC within 24 hours of being sent to Crossref; links to the full text on the preprint server via the DOI are included.
To distinguish preprints from peer reviewed articles in Europe PMC, each preprint is given a PPR ID, and is clearly labelled as a preprint, both on the abstract view and the search results (see Fig. 2). When preprints have subsequently been published as peer-reviewed articles and indexed in Europe PMC1 they are crosslinked to each other. About 14,000 preprints have so far been published in peer reviewed journals via these cross-link detection methods. All preprint content will also available in Europe PMC APIs as well as on the website.
Preprints can be claimed to ORCID iDs (indeed, in the pilot set of ~120 preprints, 77 have already been linked to ORCID iDs ) and are also included in Europe PMC routine text mining processes that identify genes/proteins, organisms, diseases, and data citations, among other key biological entities.
Making preprints discoverable in Europe PMC will make the science reported in preprints more widely discoverable and support their inclusion into workflows such as grant reporting, citing and credit and attribution.
![]()
Figure 2. Search results and abstract views in Europe PMC differentiate preprint from peer-reviewed articles.
1We use Crossref's "is-preprint-of" field as well as a basic citation metadata check to find matching peer-reviewed papers and preprints

Figure 2. Search results and abstract views in Europe PMC differentiate preprint from peer-reviewed articles.
1We use Crossref's "is-preprint-of" field as well as a basic citation metadata check to find matching peer-reviewed papers and preprints
Europe PMC as a platform for innovation
At Europe PMC, we support the use of preprints as a means to communicate research results rapidly. But we recognise that there are open questions regarding the effects of the widespread use of preprints in particular for (non-expert) readers and informations seekers, and the effects of preprints on the current life sciences publishing ecosystem. We therefore see the additional benefit of hosting preprints from several sources in Europe PMC as providing an open platform to address some of these questions. Putting preprints in the context of peer-reviewed content will help support the analysis of, for example, the impact (positive or negative) of preprints on scholarly communications overall. Do they add to churn or alleviate churn? When is a preprint cited preferentially to a peer reviewed paper? How should versions be managed across different platforms? For example, using the smart filter to retrieve all preprints that have a linked peer-reviewed paper via the Europe PMC API, and then comparing the publication dates, it is possible to reveal the median time between preprint posting and publication (Fig. 3) at around 4-5 months.
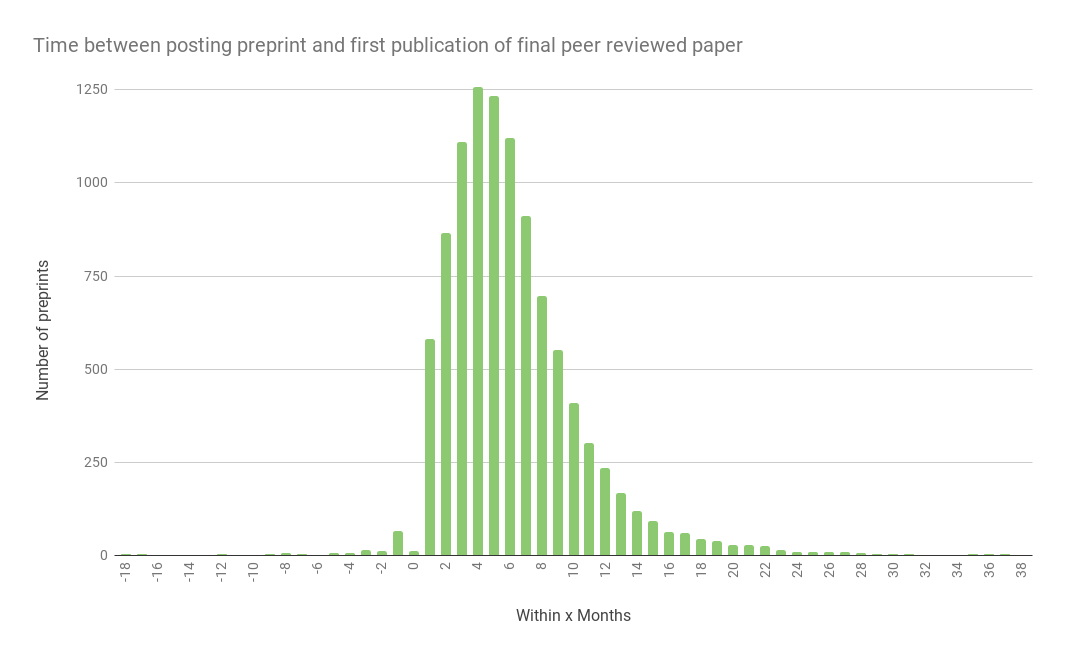
Figure 3. Time between posting a preprint and publication of a peer-reviewed article. Data taken from bioRxiv and PeerJ Preprints, using metadata supplied to Crossref. Note that a small number of preprints appear to have been posted after a peer-reviewed paper has been published, illustrating that reusing data in different contexts can provide opportunities for improved quality control. Data analysis by Michael Parkin.
The future
Aggregating a relatively small number of preprint abstracts from several different sources has already exposed some challenges in preprint management: there is variability in the scope of metadata supplied and in the handling of versions by different preprint servers. Harmonizing on these issues will require work and collaboration; we would welcome comments on these matters.
Including full text in addition to abstracts will open further questions regarding technical robustness and publishing ecosystem dynamics. With full text, we can answer deeper and perhaps more critical questions such as the impact of peer review on the evolution of a paper, and how robustly the scientific conclusions are supported re: availability of supporting data. With full text, the community can experiment on a more granular level with peer review, accreditation/badging, data integration and so on. To explore these issues fully, preprints made available in a structured format (XML) with machine-readable (and open) licenses will greatly facilitate responsible sharing, analysis and reuse of content by different communities.